The FMCG (fast moving consumer-goods) industry can no longer meet current development requirements. The traditional way of only upgrading the end of the supply chain cannot achieve high-quality business development. Huimin focuses on order fulfillment and delivery service for over one million community supermarkets, transforming and upgrading from serving retail terminal stores to promoting the digitization of the whole FMCG industry chain.
It is committed to building a B2B2C data closed-loop operating system, providing brand owners, distributors, and community supermarkets with transformed and upgraded solutions for the whole chain covering purchasing, marketing, operation, and distribution. All these commitments cannot be fulfilled without its powerful “middle platform” system.
Introducing the “middle platform”
Huimin began to transferred PHP technology stack to the Java technology stack, and shifted to microservices from 2016 to 2017, and started to build the “middle platform” in 2018.
The phase-one project of its transaction middle platform went live in early 2021, and phase-two in March 2022.
Owing to business growth and various changes, Huimin launched a strong “middle platform” development strategy to improve efficiency and reduce costs. Measures were taken to reduce the coupling degree between systems, increase scalability, and ensure low latency while extracting business commonalities. At the beginning of 2021, the company finihsed rebuilding the previous order management system (OMS) and launched a packaged business capability project for a transaction middle platform centered on the transaction process of orders, which is divided into the following four core modules: order status flow system, order management system, order fulfillment system and order cost calculation system. At the same time, based on business stratification, the project is also split into an order query system, report system, and order management backend.
To synergize technical and business requirements during the rebuilding process, the go-live process was divided into two phases: application system splitting and data splitting.
System splitting
R&D teams having to frequently adjust order management system and adapt it to multiple business lines may cause inefficiencies. In response to these problems, the following principles were formulated to split and rebuild the system:
- Avoid the logic coupling of different lines of business. Different business lines should contain and minimize influence on each other to reduce logic complexity.
- Responsibilities are divided according to the order lifecycle to ensure that each system is independent with an exclusive responsibility.
- Read/write splitting. Ensure the stability of core functions and avoid the impact of frequent iterations on core functions.
- ElasticSearch was introduced to solve the external index problem, and reduce database index pressure.

Data splitting
The purpose of data splitting is to reduce the maintenance pressure of a single table. When the amount of data reaches tens of millions, the index and field maintenance of database tables will have a great impact on the online environment. Before splitting a table, you have to consider the following questions:
- Splitting rules: what tables are data-intensive? What about the number of splits?
- Data read/write: how to solve the read/write problem after splitting tables?
- Go-live solution: how to go live smoothly?
Splitting rules
During a 3 years iteration period, the number of splits = ((amount of data added per month * 36) + Amount of historical data) / maximum amount of data in a single table.
When we use the InnoDB engine for DDL operation to maintain Alibaba Cloud RDS MySQL, we come up with the following results:
When the amount of data is less than 5 million, the execution time is about tens of seconds. Between 5 million and less than 10 million, the execution time is about 500 seconds; between 10 million and less than 50 million, the execution time is about 1000 seconds; and when more than 50 million, the execution time is more than 2000 seconds.
The upper limit for splitting a single table depends on the impact of a single table operation on business. Of course, some solutions can tackle the problem of table lock resulting from DDL operation. For example, dual-table synchronization and changes in table names can reduce the impact to within seconds.
The split number of the library table is preferably 2 to the power of N, which is conducive to later horizontal scaling.
Technology selection
After the data table is split, data hashing and query issues need to be resolved. As a SME (small & medium-sized enterprise), the cost of developing a set of sharding middleware is too high, and it will cause various risks in the early stage. A reasonable solution is to adopt a set of open source database sharding middleware.
Apache ShardingSphere is an open source ecosystem that allows you to transform any database into a distributed database system. The project includes a JDBC, a Proxy and Sidecar (Planning), which can be deployed independently and support mixed deployment. They all provide functions of data scale-out, distributed transactions and distributed governance.
Apache ShardingSphere 5.x introduces the concept of Database Plus, and the new version focuses on a plugin oriented architecture. Currently, functions including data sharding, read/write splitting, data encryption, shadow library pressure testing, as well as SQL and protocol support such as MySQL, PostgreSQL, SQL Server, Oracle, etc. are woven into the project through plugins, allowing developers to customize their own unique systems.
Why Huimin chose Apache ShardingSphere:
-
Apache ShardingSphere has a variety of functions and can solve current challenges with strong scalability.
-
The Apache ShardingSphere community is very active, which means the possibility to find support quickly.
-
The company adopts the SpringCloud technology stack which is convenient for integration and can lower costs.
-
Its performance can fully support Huimin’s existing business.
ShardingSphere supports the following 3 modes:
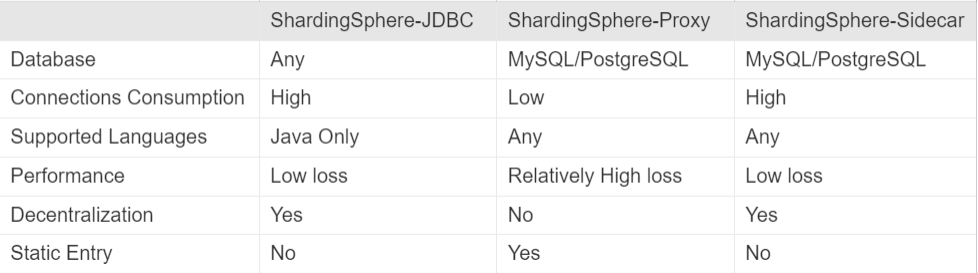
Currently, Huimin’s server-side technology stack only involves Java language, so there is no need to consider heterogeneous scenarios. Taking flexibility, code intrusion and deployment cost into consideration, the implementation of ShardingSphere-JDBC wasfinally selected.
Technology implementation
The most complicated part of the process is actually the go-live part, not the plugin integration part as would someone expect.
To achieve non-perception and rollback, we divided the go-live process into the following steps, as shown in the figure:

Step 1: Processing all the data needs to ensure the data consistency between the old and new libraries. Since there currently is no synchronization tool supporting data sharding policy, we developed a data synchronization tool to support the configuration of the sharding policy.
Step 2: Process incremental data to keep data consistency between the old and new libraries. Our implementation scheme here was to use the open source component, to listen to the binlog of the database and synchronize the database changes to the message queue, and then the data synchronization tool listens to the messages and writes them into the new library.
The architecture scheme is not complicated, but great importance was attached to the data consistency in this process. Incremental data cannot be lost, and single-line data should be written in sequential order to prevent ABA problems.
Step 3: Process the gray-release of read-traffic. At this point, we were writing an old library and reading a new library in the database. In this process, we should paid attention to the sensitivity of business to data consistency, because the delay from an old library to a new library is within seconds. Reading an old library is needed when we come across some sensitive scenarios requiring high consistency.
Step 4: Switch all read-traffic of the application to the new library, maintaining the status of writing the old library and reading the new library.
Step 5: Processing write-traffic didn’t take gray-release scenarios into consideration in order to reduce the complexity of the program. Of course, the grayscale scheme can also achieve the same effect. We supported the rollback strategy by writing data from the new library back to the old library, and then uniformly transferring all traffic to the new library within one release.
So far, the whole process of release and going live has been completed. Due to the low cost of completing the transformation with the help of ShardingSphere-JDBC middleware to rewrite SQL and merge results, there was almost no code intrusion and going live went smoothly.
There are also some issues that you may need to be aware of when accessing the ShardingSphere-JDBC scheme:
-
ShardingSphere-JDBC supports a default processing for data insertion logic. If there is no shard column in SQL, the same data will be inserted into each shard table.
-
ShardingSphere-JDBC parses only the logil table of the first SQL for batches of SQL semantic analysis, which results in an error. This problem has been reported and should be fixed in the near future. Additionally, a detailed SQL sample is provided, which lists in detail the scope of support.
-
ShardingSphere connection mode selection. The number of database connections visited by businesses should be limited for the sake of resource control. It can effectively prevent a service operation from occupying too many resources, which depletes the database connection resources and affects the normal access of other services. Especially in the case of many sub-tables in a database instance, a logical SQL without shard keys will produce a large number of actual SQL that falls on different tables in the same library. If each actual SQL occupies a separate connection, a query will undoubtedly occupy too many resources.
From the perspective of execution efficiency, maintaining a separate database connection for each shard query can make more effective use of multi-threading to improve execution efficiency. Building a separate thread for each database connection allows I/O consumption to be processed concurrently, maintains a separate database connection for each shard, and avoids premature loading of query result data into memory. A separate database connection can hold a reference to the cursor location of the query result set and move the cursor when it needs to fetch the corresponding data.
The result merging method by moving the result set cursor down is called streaming merge. It does not have to load all the result data into memory, which can effectively save memory resources and reduce the frequency of garbage collection. If each shard query cannot be guaranteed to have a separate database connection, the current query result set needs to be loaded into memory before reusing the database connection to obtain the query result set of the next shard table. Therefore, even if streaming merge could be used, it would degenerate into a memory merge in this scenario.
It is a problem for the ShardingSphere execution engine to balance the relationship between the control and protection of database connection resources and saving middleware memory resources by adopting a better merging mode. Specifically, if a SQL needs to operate on 200 tables under a database instance after its sharding in ShardingSphere, whether to create 200 connections and execute them concurrently or create one connection and execute it in sequence? How to choose between efficiency and resource control?
In response to the above scenario, ShardingSphere provides a solution. It introduces the concept of Connection Mode and divides it into MEMORY_STRICTLY mode and CONNECTION_STRICTLY mode.
MEMORY_STRICTLY
The premise of using this pattern is that ShardingSphere does not limit the number of database connections required by an operation. If the actual SQL executed needs to operate on 200 tables in a database instance, a new database connection is created for each table and processed concurrently through multi-threading to maximize the execution efficiency. When SQL meets the conditions, streaming merge is preferred to prevent memory overflow or frequent garbage collection.
CONNECTION_STRICTLY
The premise for using this pattern is that ShardingSphere strictly limits the number of database connections required for an operation. If the actual SQL executed needs to operate on 200 tables in a database instance, only one single database connection is created and its 200 tables are processed sequentially. If shards in an operation are scattered across different databases, multi-threading is still used to handle operations on different libraries, but only one database connection is created for each operation of each library. The practice prevents the problem of consuming too many database connections for one request. This pattern adopts memory merge all the time.
The MEMORY_STRICTLY mode is applicable for OLAP operations and can improve system throughput by relaxing limits on database connections. The CONNECTION_STRICTLY mode applies to OLTP operations, which usually have shard keys and are routed to a single shard. Therefore, it is a wise choice to strictly control database connections to ensure that database resources in an online system can be used by more applications.
We found that in the MEMORY_STRICTLY mode, the operation would become I/O-intensive due to the cache buffer loading strategy of MySQL InnoDB engine, resulting in SQL timeouts. Its solution is to add another layer of processing without changing database resources. If there is no shard key, verify the shard key in the external index, and then use the shard key to perform database retrieval.
ShardingSphere Benefits
1. Performance improvement Through architecture rebuilding, it can effectively control the amount of single table data, and greatly reduce the slow SQL, down nearly 50%.
2. Save R&D resources and lower cost
The introduction of Apache ShardingSphere does not require the re-development of sharding components, which reduces the R&D cost and lowers the risks.
3. Strong scalability
Apache ShardingSphere has good scalability in terms of data encryption, distributed transactions, shadow library and other aspects.
Conclusion In his book Building Microservices, Sam Newman writes, “ Our requirements shift more rapidly than they do for people who design and build buildings — as do the tools and techniques at our disposal. The things we create are not fixed points in time. Once launched into production, our software will continue to evolve as the way it is used changes. For most things we create, we have to accept that once the software gets into the hands of our customers we will have to react and adapt, rather than it being a never-changing artifact. Thus, our architects need to shift their thinking away from creating the perfect end product, and instead focus on helping create a framework in which the right systems can emerge, and continue to grow as we learn more (Sam Newman, 2015: 15).” Apache ShardingSphere is doing exactly what the book says, and is definitely on a promising path.
Author
Zhai Yang
Software architect at Zhongshang Huimin E-Commerce platform team.
Participated in the 0–1 process of middle platform construction, mainly responsible for the R&D and building the transaction and commodity middle platform and the search platform.
